
The AP Statistics test is a comprehensive assessment of the knowledge and skills acquired in the first unit of the course. This exam is designed to gauge students’ understanding of fundamental statistical concepts and their ability to apply these concepts to real-world data. The Unit 1 test covers topics such as descriptive statistics, probability, and experimental design.
Descriptive statistics is the branch of statistics that deals with summarizing and analyzing data. Students will be tested on their ability to calculate and interpret measures of central tendency, such as mean, median, and mode, as well as measures of spread, such as range and standard deviation.
Probability is the study of uncertainty and the likelihood of events. In the context of the Unit 1 test, students will be expected to understand basic probability concepts, such as the probability of an event occurring and the complementary probability of an event not occurring. They will also be assessed on their ability to use probability to solve problems, including calculating probabilities of independent and dependent events.
Experimental design is the process of planning and conducting experiments to collect data and answer research questions. Students will be evaluated on their knowledge of different types of studies, such as observational studies and experiments, and their understanding of sampling methods and biases. They will also be tested on their ability to interpret and analyze data from experiments and draw conclusions based on the results.
Overall, the Unit 1 AP Statistics test is an important assessment that measures students’ proficiency in key statistical concepts and their ability to apply these concepts to real-world situations. It serves as a foundation for the rest of the AP Statistics course and prepares students for more advanced statistical analysis in later units.
Unit 1 AP Statistics Test
Preparing for the Unit 1 AP Statistics test is essential for students who want to succeed in the course. This test is designed to assess students’ understanding of the fundamental concepts of statistics and their ability to apply these concepts to solve real-world problems. It covers topics such as data analysis, experimental design, and probability.
One key aspect of the Unit 1 AP Statistics test is data analysis. Students are expected to be able to summarize and interpret data using various statistical measures, such as mean, median, and standard deviation. They should also be able to create graphical representations of data, such as histograms and scatter plots, and analyze these graphs to draw conclusions about the data.
Another important topic covered in the test is experimental design. Students need to understand the principles of designing experiments and surveys, including the concepts of randomization and control groups. They should be able to evaluate the validity and reliability of studies and identify potential sources of bias.
Probability is another key concept that students need to master for the Unit 1 AP Statistics test. They should be able to calculate probabilities using both theoretical and empirical methods and apply these calculations to solve probability problems. Additionally, they should understand the concepts of independence and conditional probability, as well as the laws of probability.
Overall, the Unit 1 AP Statistics test is designed to assess students’ knowledge and skills in data analysis, experimental design, and probability. To succeed on this test, students should review and practice these key concepts, as well as familiarize themselves with the format and types of questions typically seen on the AP Statistics exam.
Overview of AP Statistics
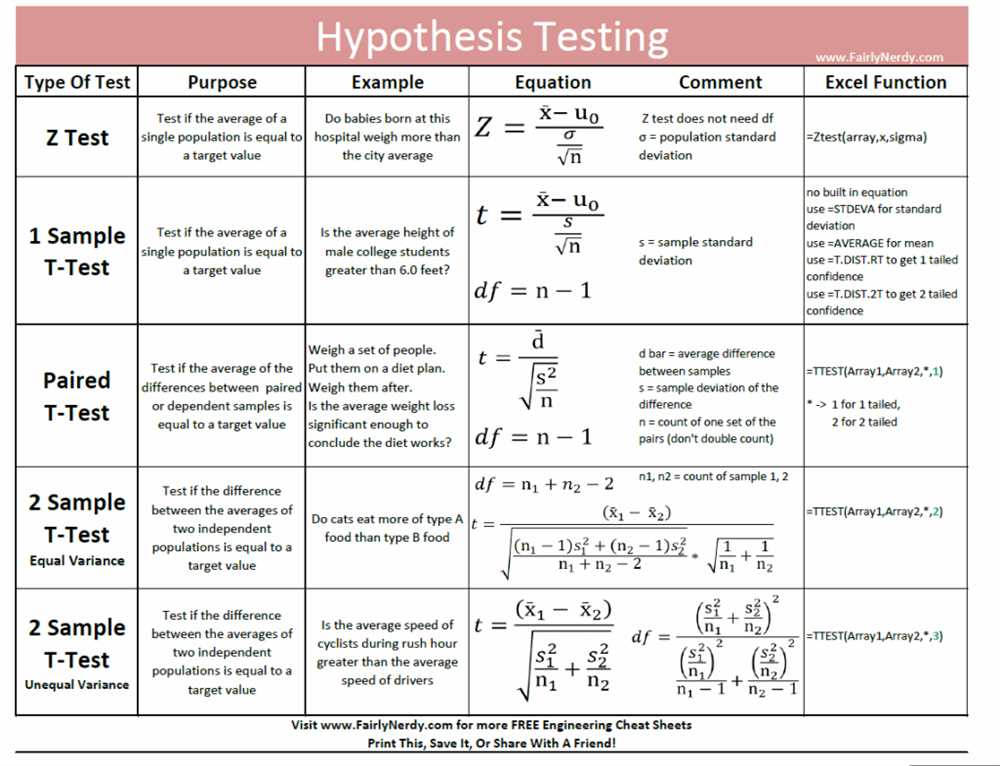
AP Statistics is a course designed to introduce students to the concepts and methods of statistics. It is a college-level course that covers topics such as data collection, data analysis, probability, and inferential statistics. The ultimate goal of the course is to help students develop the skills necessary to analyze data and make informed decisions based on that data.
The AP Statistics exam consists of multiple-choice and free-response questions that assess students’ understanding of the course material. It is divided into four main sections: exploratory analysis, planning and conducting studies, probability and simulation, and statistical inference. The exam is rigorous and requires students to apply their knowledge to real-world scenarios and problems.
Throughout the course, students will learn how to effectively collect and summarize data, interpret graphical representations, and perform basic statistical calculations. They will also study probability theory and learn how to use probability models to make predictions and test hypotheses. Additionally, students will gain an understanding of sampling techniques, experimental design, and the principles of statistical inference.
AP Statistics is a valuable course for students who are interested in careers or fields that involve working with data, such as economics, psychology, sociology, and market research. It provides a solid foundation in statistical concepts and methods, which are essential for making informed decisions and drawing meaningful conclusions from data. By successfully completing the AP Statistics course and exam, students can also earn college credit and demonstrate their proficiency in statistical analysis to potential colleges and employers.
Preparing for the Unit 1 Test
In order to prepare for the Unit 1 test in AP Statistics, it is important to review the key concepts and topics that have been covered in the unit. This includes understanding the basics of data analysis, probability, and statistical inference.
Key concepts:
- Data analysis: This involves understanding how to collect, organize, describe, and display data in various ways such as tables, graphs, and numerical summaries.
- Probability: This involves understanding the concepts of probability, including calculating probabilities of events and understanding the laws of probability.
- Statistical inference: This involves understanding how to make inferences and draw conclusions about a population based on sample data, including hypothesis testing and confidence intervals.
Review strategies:
- Review class notes: Go over your class notes and make sure you understand the key concepts and examples discussed in class.
- Complete practice problems: Practice solving practice problems that cover the different types of questions that may be asked on the test.
- Utilize resources: Make use of textbooks, online resources, and study guides to supplement your learning and reinforce your understanding of the material.
- Form study groups: Collaborate with classmates and work through problems together to reinforce your understanding and learn from one another.
- Ask for help: If there are any concepts or topics that you are struggling with, don’t hesitate to ask your teacher or classmates for clarification.
By reviewing these key concepts and using effective study strategies, you can feel confident and prepared for the Unit 1 test in AP Statistics.
Understanding Experimental Design
Experimental design is an essential aspect of conducting scientific research. It involves the careful planning and execution of experiments in order to effectively investigate and analyze the relationship between variables. A well-designed experiment allows researchers to draw valid and reliable conclusions, providing valuable insights into the phenomena being studied.
Randomization is a fundamental principle in experimental design. It involves assigning participants or subjects to different treatment groups or conditions randomly. This helps eliminate bias and ensures that the groups are comparable at the baseline, reducing the influence of confounding variables. Randomization also allows for statistical inference and generalization of the results to a larger population.
Control group is another important aspect of experimental design. It serves as a baseline against which the effects of the treatment or intervention can be compared. The control group does not receive the experimental treatment and is used as a reference to assess the effectiveness of the intervention. By comparing the outcomes of the control and experimental groups, researchers can determine the causal effects of the treatment.
Furthermore, replication is crucial in experimental design to ensure the reliability and validity of the results. Replication involves repeating the experiment multiple times with different participants or subjects to determine if the findings can be consistently reproduced. This helps establish the robustness of the results and strengthens the overall validity of the study.
In addition to randomization, control groups, and replication, there are various other factors to consider in experimental design, such as sample size determination, blinding, and data collection methods. These factors contribute to the overall quality and rigor of the study. By understanding the principles of experimental design, researchers can design and conduct experiments that yield meaningful and reliable results, advancing scientific knowledge in their respective fields.
Exploring Data with Graphs
Data can often be complex and difficult to understand, but graphs can help us make sense of it all. By presenting data visually, graphs provide a clear and concise way to communicate information. There are several types of graphs commonly used in statistics to explore and analyze data.
Bar graphs are a simple and effective way to display categorical data. They use rectangular bars of varying heights to represent the different categories and their corresponding frequency or proportion. Bar graphs are especially useful when comparing data across different categories or groups.
Histograms are similar to bar graphs, but are used to display quantitative data. Instead of categorical variables, histograms use intervals or bins on the x-axis to represent ranges of data. The height of each bar represents the frequency or proportion of data within that interval. Histograms are particularly useful in visualizing the shape and distribution of continuous data.
Scatter plots are used to show the relationship between two continuous variables. Each point on the graph represents an individual observation with coordinates corresponding to its values on the x and y axes. Scatter plots are useful in identifying patterns, trends, and potential correlations between variables.
Line graphs are used to visualize changes in a variable over time. The x-axis represents the time period, while the y-axis represents the value of the variable. Line graphs are especially effective in illustrating trends and patterns, and can be used to make predictions or forecast future values.
Pie charts are used to display parts of a whole. They represent the relative proportions or percentages of different categories by dividing a circle into sectors. Each sector size corresponds to the proportion of each category. Pie charts are useful when comparing or highlighting the contribution of different categories to the whole.
Overall, graphs are powerful tools in exploring and interpreting data. They allow us to see patterns, trends, and relationships that may not be immediately apparent from raw data. By visually representing data, graphs provide a clear and concise way to communicate information and make informed decisions.
Calculating Measures of Central Tendency and Variation
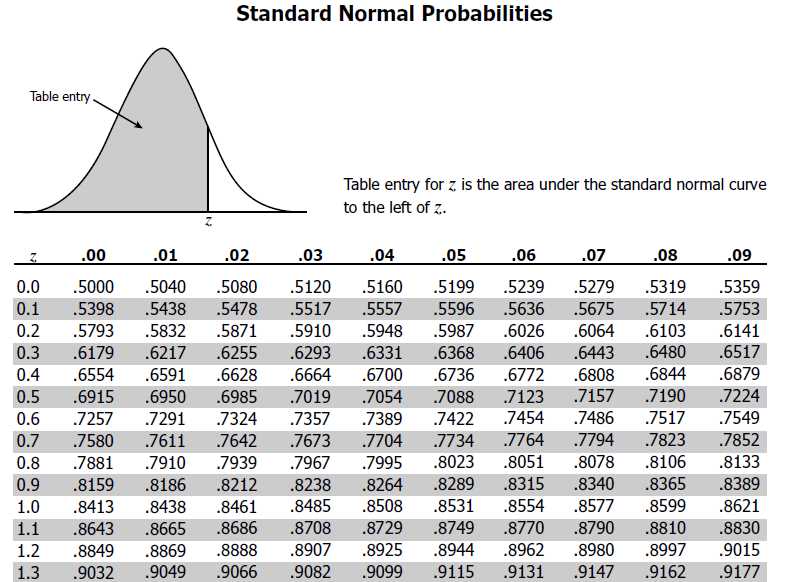
Measures of central tendency and variation are essential tools in statistics for analyzing data and describing its characteristics. Central tendency measures, such as the mean, median, and mode, provide a summary of the typical or central value of a dataset. Variation measures, such as the range, interquartile range, and standard deviation, describe the spread or dispersion of the data around the central value.
The mean is the most commonly used measure of central tendency and is calculated by summing all the values in the dataset and dividing by the number of values. It is sensitive to extreme values and can be affected by outliers. The median, on the other hand, is the middle value when the dataset is arranged in ascending or descending order. It is less affected by extreme values and is preferred when analyzing skewed or non-normal distributions. The mode is the value that occurs most frequently in the dataset and is useful for categorical or nominal data.
Variation measures provide information about how spread out the data points are. The range is the difference between the maximum and minimum values in the dataset and gives a rough estimate of the spread. The interquartile range (IQR) is the difference between the upper quartile (Q3) and lower quartile (Q1) and represents the spread of data around the middle 50%. The standard deviation is a more precise measure of variation and indicates the average distance between each data point and the mean. A larger standard deviation implies greater variability in the dataset.
Understanding and calculating these measures is crucial for interpreting and analyzing data in statistics. They provide valuable insights into the distribution and characteristics of a dataset, enabling researchers and analysts to make informed decisions and draw reliable conclusions.
Interpreting Histograms and Boxplots
When analyzing data, two common graphical displays that statisticians use are histograms and boxplots. Histograms are visual representations that show the distribution of a dataset by dividing it into bins and plotting the frequency or relative frequency of each bin. Boxplots, on the other hand, provide a summary of a dataset’s distribution by displaying the minimum, maximum, median, and quartiles.
In order to interpret a histogram, one must first understand the shape of the distribution. A histogram can be symmetrical, where the left and right sides mirror each other, or skewed, where the distribution is shifted to one side. Additionally, it is important to observe whether the distribution is unimodal (one peak) or multimodal (multiple peaks). The height of each bar in a histogram represents the frequency or relative frequency of data points falling within each bin.
Boxplots provide a visual summary of the various summary statistics of a dataset and can be used to identify any outliers. The box in a boxplot represents the interquartile range (IQR), which is the range between the first quartile (Q1) and third quartile (Q3). The line within the box represents the median, which is the middle value of the dataset. The “whiskers” extend from the ends of the box and represent the minimum and maximum values within 1.5 times the IQR. Any data points falling outside this range are considered outliers and are represented by individual points.
Overall, histograms and boxplots are valuable tools for interpreting and analyzing data. By looking at the shape, symmetry, peaks, and summary statistics of distributions, statisticians can gain insights into the patterns and characteristics of a dataset.